Les systèmes d'information modernes sont de plus en plus décentralisés et dynamiques. Ils tirent parti de l'évolution des techniques pour rester compétitifs et bénéficier des avantages apportés par des ordinateurs toujours plus petits, moins chers et plus puissants, ainsi que par la prolifération de services de communications. En même temps, le système d'information doit faire face à la nécessité d'interagir avec différents types d'ordinateurs, de réseaux de communications et d'unités utilisateur. Une transaction peut consister en des opérations effectuées sur l'ordinateur portable d'un client, l'ordinateur personnel d'une filiale et un ordinateur central, mais le système doit cependant fournir la qualité de service et l'intégrité maximales. Le traitement transactionnel réparti permet d'assurer que l'application ne prend pas du tout en compte le lieu d'exécution des opérations, tant que sont assurées la qualité du service et l'intégrité des données.
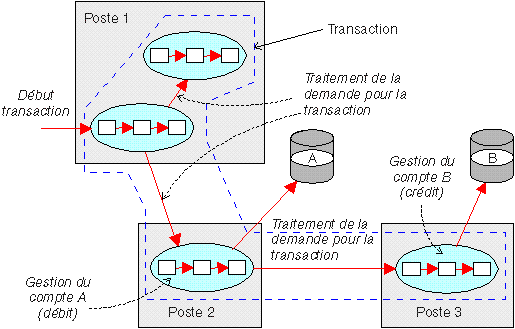
Dans le traitement transactionnel réparti le plus simple, une transaction exécute plusieurs programmes sur différents processus sur le même poste. Dans un environnement réellement réparti, les processus sont situés sur des postes différents, voire sur des plateformes différentes :
L'application ne perçoit pas de différence de fonctionnement entre la transaction s'exécutant dans un seul processus et celle qui s'exécute dans plusieurs processus répartis. Elle effectue les mêmes appels de programme, de données et autres ressources et laisse le serveur de transactions déterminer l'emplacement des ressources. Les utilisateurs peuvent cependant obtenir un service de meilleure qualité. Par exemple, un serveur de transactions peut être optimisé en vue d'une interaction avec l'utilisateur afin d'offrir de brefs temps de réponse et de transmettre les opérations qui demandent un travail intensif à un autre serveur de transactions pour qu'il les traite.
En recourant à des transactions réparties, l'entreprise gagne en souplesse de configuration des systèmes car des parties de la logique de traitement et des données peuvent être placées à l'endroit où elles peuvent être utilisées de la façon la plus efficace. Les fonctions peuvent être adaptées aux besoins locaux (par exemple, du pays ou de l'entreprise).
L'interconnexion permet le partage en temps réel de la logique de traitement et des données. Elle offre également plus de disponibilité et de fiabilité grâce à l'existence des mêmes fonctions sur des ordinateurs séparés. La distribution permet également une croissance progressive du système par ajout ou remplacement d'ordinateurs spécifiques, sans affecter l'utilisation des autres ordinateurs du système.
Le modèle client-serveur est une façon courante d'organiser des logiciels pour qu'ils s'exécutent sur des systèmes répartis. Un client, qui peut aller de l'ordinateur portable d'un client de l'entreprise à l'ordinateur d'une filiale, comporte la logique d'affichage. Les logiques applicatives et de données peuvent être réparties sur des serveurs au fonctionnement optimal sur le réseau. Le client demande une fonction et le serveur exécute cette fonction. L'activité d'un serveur requiert souvent la gestion des ressources, qui recouvre la synchronisation et la gestion de l'accès aux ressources et la réponse aux demandes des clients par des informations d'état ou des données. Les programmes clients traitent en général les entrées et sorties utilisateur et demandent souvent des données ou des modifications de données pour le compte d'un utilisateur.
Par exemple, un client peut fournir un formulaire dans lequel un utilisateur (par exemple, une personne travaillant sur un terminal d'entrée de données) peut entrer des commandes de produit. Le client envoie ces informations au serveur, qui vérifie la base de données du produit et exécute les tâches nécessaires à la facturation et la livraison. En général, un serveur est utilisé par plusieurs clients. Par exemple, des dizaines ou des centaines de clients peuvent interagir avec quelques serveurs qui contrôlent l'accès à la base de données.
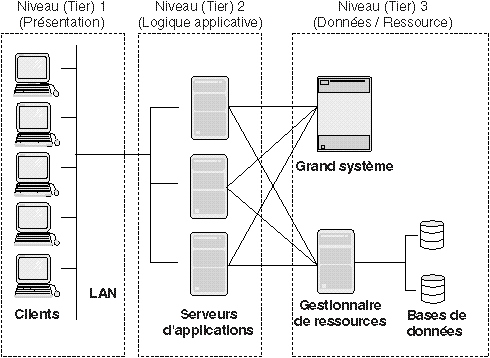
Les architectures réparties peuvent revêtir diverses formes. Il existe le modèle client-serveur à trois niveaux dont la présente un exemple. Le premier niveau contient le logiciel de présentation (applications client qui dialoguent avec les utilisateurs via des écrans ou des interfaces de ligne de commande). Dans le second niveau, les applications client envoient des demandes aux applications serveur. Ces applications contiennent la logique applicative. Les serveurs exécutent des fonctions telles que la mise à jour ou l'extraction de données en réponse aux demandes des clients. Le troisième niveau contient des données et des ressources, ce qui les sépare de la logique applicative. Les serveurs communiquent avec les gestionnaires de ressources. Un gestionnaire de ressources est une application qui gère des données partagées (par exemple, une base de données Oracle utilisée pour stocker des informations comptables). Les serveurs peuvent utiliser une grande variété de ressources (par exemple, des grands systèmes et des systèmes de gestion de bases de données relationnelles) pour effectuer leur travail.
Maintenant que vous avez su acquérir les notions essentielles concernant les STT et ses diverses applications nous vous invitons à aller jeter un coup d'oeil sur certains concepts associés.
[Page Principale]
[Historique]
[Notions de Base] [Le STT?]
[Le STTL?] [Coupures de Journaux] [Concept
Associées] [QUIZ!] [Références]
[Auteurs]