NOTIONS DE BASE
Questions de vous faire les dents et de vous préparer adéquatement aux notions à venir, nous vous proposons un court récapitulatif des principales notions que vous vous devez de connaître avant d'aller plus à fond dans la découverte des STT. Vous avez aussi le loisir de consulter une brève liste de concepts associés au STT.
Introduction à la Gestion des Données
Les systèmes transactionnels fournissent à leurs utilisateurs un accès aux données (comptes clients, par exemple) fiable, précis et rapide. Ces données utilisateur peuvent se présenter sous forme de fichiers, de files d'attente et d'entrées de base de données (le système transactionnel utilise également d'autres données, appelées données système, pour contrôler son fonctionnement).
Les données peuvent être fournies par un ou plusieurs gestionnaires de ressources : par exemple, un serveur de fichiers structurés (SFS), un gestionnaire de bases de données relationnelles (SGBDR), ou un gestionnaire de files d'attente.
Les données peuvent être enregistrées sous forme de :
Les données sont des ressources communes disponibles pour un ou plusieurs serveurs. N'importe quelle tâche peut lire, écrire ou supprimer et partager des données avec d'autres tâches.
Pour l'accès aux données, la différence la plus importante entre les données enregistrées dans une base de données et celles enregistrées dans des fichiers ou des files d'attente est la structure que le SGBDR impose aux données. Cette structure détermine l'interface de programmation d'applications pour les données et le degré de difficulté de stockage et d'extraction des données pour tel ou tel traitement. Si les données sont complexes, la structure peut être le facteur le plus important.
Fichiers
Les données des fichiers sont organisées en un ensemble d'enregistrements. Un enregistrement est un regroupement d'informations associées de taille prédéfinie et avec un nombre et une structure de zones prédéfinis. Chaque enregistrement d'un fichier comporte le même nombre et la même structure de zones, celles-ci contenant des parties spécifiques des informations de l'enregistrement. Par exemple, chaque enregistrement peut contenir des informations sur un compte bancaire, avec des zones pour le numéro de compte, le nom du titulaire, le solde, etc. L'organisation du fichier est la façon dont les enregistrements sont placés dans le fichier.
Un fichier comporte un index primaire, qui définit l'ordre physique de ses enregistrements. Un fichier comporte également un certain nombre d'index secondaires, qui déterminent différents ordres d'accès aux enregistrements du fichier. Un index peut être considéré comme une liste de pointeurs associés aux enregistrements d'un fichier, où l'index primaire répertorie l'ordre réel des enregistrements et chaque index secondaire répertorie les pointeurs dans un ordre différent. Les programmes d'application peuvent lire, mettre à jour, supprimer et consulter les données dans des fichiers locaux ou éloignés.
Trois types d'organisations de fichiers :
Fichier en ordre d'arrivée (ESDS)Les enregistrements d'un fichier en ordre d'arrivée sont stockés dans l'ordre dans lequel ils sont écrits dans le fichier. Les nouveaux enregistrements s'ajoutent à la fin du fichier. Lorsque des enregistrements sont supprimés, l'espace disque qu'ils utilisaient n'est pas systématiquement récupéré et réutilisé ; il peut être récupéré par la réorganisation du fichier.
Les fichiers en ordre d'arrivée sont souvent utilisés lorsqu'il y a accès aux enregistrements dans l'ordre chronologique d'écriture ; par exemple, pour les fichiers d'enregistrement et les fichiers de trace de contrôle. L'index primaire, qui n'est pas stocké dans le fichier, répertorie les enregistrements dans l'ordre dans lequel ils ont été ajoutés au fichier.
Les enregistrements peuvent être de longueur fixe ou variable. Lors de la mise à jour d'un enregistrement existant, l'enregistrement mis à jour ne peut dépasser sa longueur d'origine.
Un fichier en ordre relatif est un tableau d'emplacements de longueur fixe dans lesquels les enregistrements peuvent être stockés. Un enregistrement peut être ajouté au premier emplacement disponible depuis le début du fichier, à la fin du fichier ou à un emplacement disponible du fichier. Les enregistrements peuvent être de longueur fixe ou variable, ne dépassant pas la longueur d'emplacement prédéfinie pour le gestionnaire de fichiers. Vous pouvez mettre à jour ou supprimer tout enregistrement. Tout emplacement rendu disponible par la suppression d'un enregistrement peut être réutilisé pour l'insertion ultérieure d'un autre enregistrement. L'index primaire fait physiquement partie des données de l'enregistrement.
Un fichier à enregistrements indexés comporte des enregistrements identifiés chacun par une zone clé située à un emplacement prédéfini de l'enregistrement. Les clés ne doivent pas obligatoirement être uniques. Les enregistrements d'un fichier sont triés automatiquement selon la valeur de leurs clés et groupées par clés identiques et adjacentes. Cela permet de faciliter les recherches portant sur des plages d'enregistrements.
Dans un fichier à enregistrements indexés, les enregistrements n'ont pas d'index numérique comme dans les fichiers en ordre d'arrivée et en ordre relatif. Vous pouvez baser l'index primaire sur n'importe quelle zone ou combinaison de zones. L'ordre des enregistrements dans un fichier à enregistrements indexés est fonction de l'index primaire. Lorsque vous ajoutez ou supprimez des enregistrements, le gestionnaire de files d'attente met automatiquement à jour l'index primaire et, si nécessaire. déplace les enregistrements pour les maintenir indexés. L'espace disque libéré par la suppression des enregistrements est automatiquement réutilisé.
Un index primaire de fichier est utilisé pour accéder à chaque enregistrement du fichier par une clé primaire unique. Vous pouvez également définir un ou plusieurs index secondaires, qui vous permettent d'accéder au même groupe d'enregistrements de diverses manières. Par exemple, un fichier personnel peut comporter un index primaire utilisant seulement les matricules des employés, et un index secondaire utilisant le nom des employés. Vous pouvez alors extraire un enregistrement au moyen du matricule ou du nom.
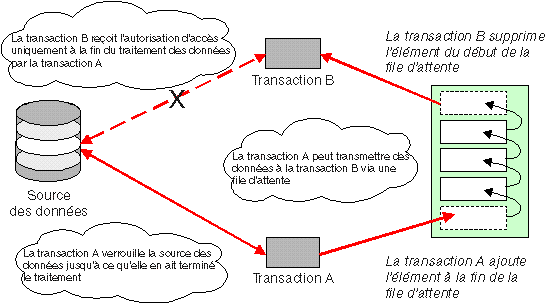
Les files d'attente sont des fonctions de stockage séquentiel, en général temporaires, rendues nécessaires par la nature dynamique du traitement transactionnel. Elles sont généralement utilisées pour le traitement des demandes ou la transmission de données d'une transaction à l'autre, comme le montre la Par exemple, les données produites au cours d'une transaction ne sont en général imprimées que bien après l'achèvement de la tâche ; elles attendent dans une file d'attente que le programme d'impression les traite lorsqu'il n'y a plus de tâche urgente à exécuter.
Une file d'attente est une suite d'éléments de données identifiée par un nom symbolique. Chaque élément contient des données orientées enregistrement d'un type spécifique de l'application qui doit les traiter. Des éléments de différents types peuvent être placés dans la même file d'attente.
Avec une file d'attente classique, les transactions ajoutent (placent en file d'attente) les éléments à la fin de la file d'attente et retirent (suppriment de la file d'attente) les éléments du début de la file d'attente en mode FIFO (premier entré, premier sorti). Chaque élément doit être lu dans l'ordre et, une fois lu, est enlevé de la file d'attente. Les files d'attente prennent en charge de nombreuses demandes simultanées de placement en file d'attente et d'extraction d'éléments, leur taille augmentant ou diminuant selon le volume des demandes. Une transaction peut replacer des éléments dans une autre file d'attente pour un autre traitement.
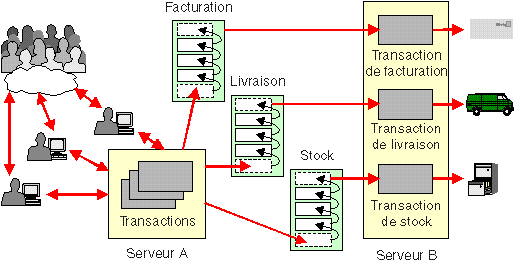
Vous pouvez utiliser des files d'attente de façon différente ; par exemple, comme un bloc-notes d'éléments à écrire, mettre à jour, lire et supprimer par n'importe quelle transaction. Vous pouvez également extraire de la file d'attente des éléments dans un ordre différent de celui dans lequel ils ont été placés dans cette file.La prochaine figure présente des files d'attente utilisées pour la prise en charge de l'application d'une entreprise de vente par téléphone. Chaque employé exécute une application (sur un serveur de transactions A) et confirme les ventes à la clientèle en temps réel pour un meilleur service. Chaque transaction ajoute les données associées à la commande de vente à des files d'attente pour traitement ultérieur. La tâche volumineuse de traitement de la commande est divisée en applications de facturation, d'envoi et de mise à jour du stock. Ces application s'exécutent séparément du dialogue téléphonique initial, sous forme de transactions sur le serveur de transactions B. Ces transactions extraient les données qu'elles doivent traiter.
Les programmes d'application peuvent accéder aux SGBDR au moyen de commandes SQL intégrées.
Un journal est un ensemble de fichiers séquentiels à utilisation particulière. Les journaux peuvent contenir tout ou partie des données nécessaires à l'utilisateur pour reconstruire les événements ou les modifications apportées aux données. Par exemple, un journal peut jouer le rôle de trace de contrôle, un fichier de modifications contenant les mises à jour et ajouts apportés à une base de données ou un enregistrement des transactions transmises par le système (souvent appelé historique). N'importe quelle tâche peut écrire dans le même journal. Les journaux sont fondamentaux dans la reprise des transactions.
Lorsqu'une tâche crée un enregistrement de journal, elle peut attendre que les données de sortie soient produites en totalité. Le programme d'application est alors assuré que l'enregistrement de journal est écrit dans l'unité de stockage externe du journal avant que le traitement ne se poursuive ; la tâche est alors dite synchronisée avec l'opération de sortie.
Le programme d'application peut également demander une journalisation asynchrone des données de sortie. Dans ce cas, un enregistrement de journal est créé dans un fichier de mémoire tampon du système d'exploitation et, éventuellement, les données du tampon sont envoyées sur une unité externe. La tâche à l'origine de la demande peut ainsi garder le contrôle et poursuivre le traitement. Ultérieurement, la tâche peut vérifier et attendre la disponibilité des données de sortie (mode synchrone).
Nous espérons que vous avez bien emmagasinés les informations de cette page. Pour continuer, vous devez cliquer STT ( qui vous introduira aux notions clés du STT ) où vous pourrez découvrir Les Systèmes de Traitement Transactionnels en Ligne et les Systèmes de Traitement Transactionnel Répartis (STTR ), deux applications pratiques des STT
[Page
Principale] [Historique] [Le
STT?]
[Le STTL?] [Le STTR?] [Coupures
de Journaux] [Concept Associées] [QUIZ!] [Références]
[Auteurs]